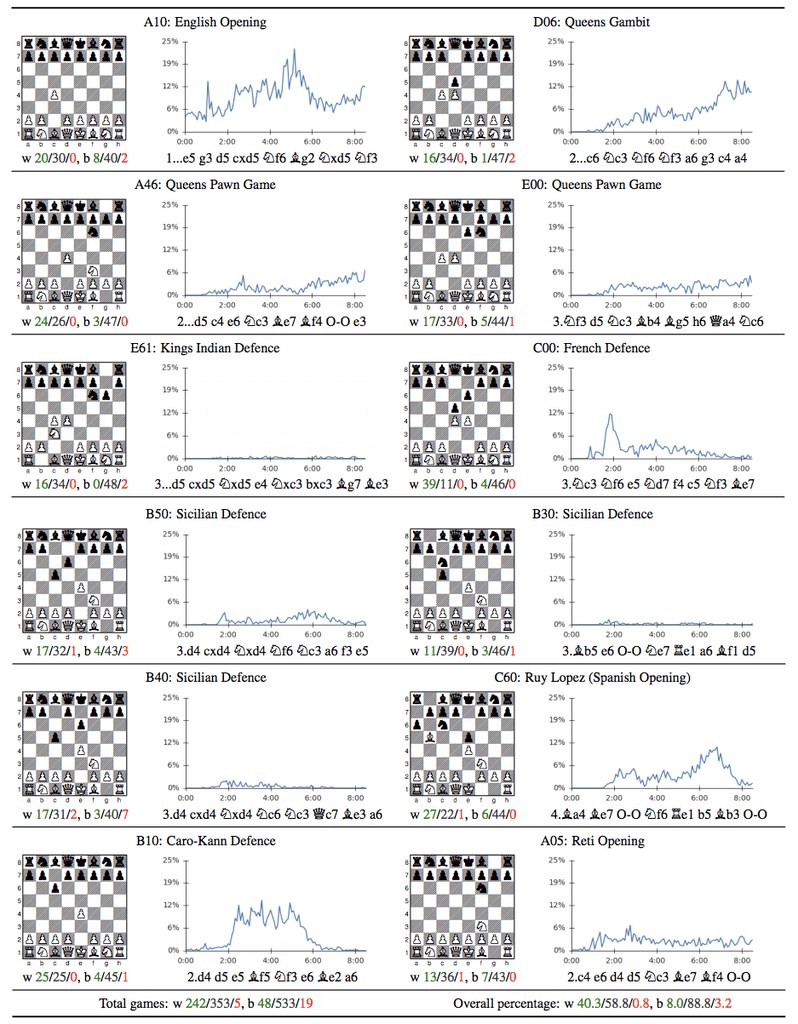
Googles Abteilung DeepMind hat ihr Programm AlphaGoZero weiterentwickelt
zu AlphaZero, das Stockfisch kürzlich in einem 100 Partien-Wettkampf mit
28 : 72 : 0 (Gewinn/Remis/Verlust) schlug. Das Besondere an AlphaGoZero
und AlphaZero ist, dass diesen Programmen nur die Regeln von Go bzw. Schach
beigebracht wurden, kein Hintergrundwissen, keine Datenbanken (zero Wissen).
Danach spielte AlphaZero nur 4 Stunden (!) gegen sich selbst,
verbesserte sich durch Lernalgorithmen für neuronale Netzwerke und
gewann anschließend den Wettkampf gegen Stockfisch.
Es gewann in Shogi gegen das Programm Elmo nach 2 Stunden.
Siehe
arxiv.org/pdf/1712.01815.pdf
zur Originalpublikation von gestern (5. Dez. 2017).
Allerdings wurde die verwendete unterschiedliche Hardware für AlphaZero bzw. Stockfisch
als nicht gleichwertig kritisiert, siehe
chess.com/blog/maelic/new-computer-chess-champion-not-yet
zu AlphaZero, das Stockfisch kürzlich in einem 100 Partien-Wettkampf mit
28 : 72 : 0 (Gewinn/Remis/Verlust) schlug. Das Besondere an AlphaGoZero
und AlphaZero ist, dass diesen Programmen nur die Regeln von Go bzw. Schach
beigebracht wurden, kein Hintergrundwissen, keine Datenbanken (zero Wissen).
Danach spielte AlphaZero nur 4 Stunden (!) gegen sich selbst,
verbesserte sich durch Lernalgorithmen für neuronale Netzwerke und
gewann anschließend den Wettkampf gegen Stockfisch.
Es gewann in Shogi gegen das Programm Elmo nach 2 Stunden.
Siehe
arxiv.org/pdf/1712.01815.pdf
zur Originalpublikation von gestern (5. Dez. 2017).
Allerdings wurde die verwendete unterschiedliche Hardware für AlphaZero bzw. Stockfisch
als nicht gleichwertig kritisiert, siehe
chess.com/blog/maelic/new-computer-chess-champion-not-yet
Dieser Beitrag wurde bereits 1 mal editiert, zuletzt von Manni5 ()


 )
)